Towards Fairer Datasets: Filtering and Balancing the Distribution of the People Subtree in the ImageNet Hierarchy
Kaiyu Yang (Princeton University), Klint Qinami (Princeton University), Li Fei-Fei (Stanford University), Jia Deng (Princeton University), Olga Russakovsky (Princeton University)
September 17, 2019
This research post describes the effort to improve ImageNet data, initiated, conceptualized, and executed solely by the above authors as part of a NSF funded project that started one year ago on September 1, 2018. The full technical report is published at FAT* 2020.
[paper] [project]
As AI technology advances from research lab curiosities into people’s daily lives, ensuring that AI systems produce appropriate and fair results has become an important scientific question. This requires multiple iterations of research on the data, algorithms, and design choices in all stages of building an AI system.To this end, ImageNet, as an influential research dataset, deserves to be critically examined. Below we summarize the most recent effort from our research team on this topic. In this work, we consider three key factors within ImageNet that may lead to problematic behavior in downstream computer vision technology: (1) the stagnant concept vocabulary, (2) the exhaustive illustration of all concepts with images, and (3) the inequality of representation in the images within concepts. We seek to illuminate the root causes of these concerns and take the first steps to mitigate them constructively. The full technical report was submitted for peer review in August 2019 and will be made available shortly.
ImageNet is an image database with a total of 14 million images and 22 thousand visual categories. As it is publicly available for research and educational use, it has been widely used in the research of object recognition algorithms, and has played an important role in the deep learning revolution.
As computer vision technology becomes widespread in people's Internet experience and daily lives, it is increasingly important for computer vision models to produce results that are appropriate and fair, particularly in domains involving people. However, there are notorious and persistent issues. For example, face recognition systems have been demonstrated to have disproportionate error rates across race groups, in part attributed to the underrepresentation of some skin tones in face recognition datasets [3].
ImageNet has been mostly used for researching object recognition algorithms on the subset of 1000 categories selected for the ImageNet Challenge[2], with only 3 people categories (scuba diver, bridegroom, and baseball player). However, the full ImageNet contains 2,832 people categories under the person subtree, which can be used to train classifiers of people. Such use can be problematic and raises important questions about fairness and representation. In this post, we describe our research efforts over the past year to identify and remedy such issues.
The construction of ImageNet
ImageNet was constructed in 2009 through Internet search and crowdsourcing. The research team obtained a vocabulary of categories from WordNet, an English database that represents each category as a synonym set (or “synset”) consisting of synonymous words, for example, dogsled, dog sled, dog sleigh. WordNet was manually constructed by psychologists and linguists at Princeton University starting in 1985, and has been widely used in the research of Natural Language Processing.
For each synset, the ImageNet team in 2009 automatically downloaded images by querying search engines. At that time, search engines did not have accurate algorithms to understand the content of images, so they retrieved images mostly based on their captions or tags. This resulted in many irrelevant images for each category.
To remove the irrelevant images, they hired workers on Amazon Mechanical Turk (MTurk) to verify whether each image correctly depicts the synset. Due to the sheer scale of the annotation effort (over 50K workers and over 160M candidate images), an automated system was developed to download images from the search engines and assign the images to MTurk workers.
Identifying and Remedying Issues of Fairness and Representation
Over the past year, we have been conducting a research project to systematically identify and remedy fairness issues that resulted from the data collection process in the person subtree of ImageNet. So far we have identified three issues and have proposed corresponding constructive solutions, including removing offensive terms, identifying the non-visual categories, and offering a tool to rebalance the distribution of images in the person subtree of ImageNet.
While conducting our study, since January 2019 we have disabled downloads of the full ImageNet data, except for the small subset of 1,000 categories used in the ImageNet Challenge. We are in the process of implementing our proposed remedies.
Below we summarize our findings and remedies, with further details provided in a forthcoming technical report, which we submitted in August 2019 for peer review.
Concept vocabulary. The first issue is that WordNet contains offensive synsets that are inappropriate to use as image labels. Although during the construction of ImageNet in 2009 the research team removed any synset explicitly denoted as “offensive”, “derogatory”, “pejorative,” or “slur” in its gloss, this filtering was imperfect and still resulted in inclusion of a number of synsets that are offensive or contain offensive synonyms. To remedy this issue, we have performed a manual annotation of the synsets in terms of offensiveness, using a group of in-house annotators. Each synset is classified as either “offensive” (offensive regardless of context), “sensitive” (offensive depending on context), or “safe”. “Offensive” synsets are inherently offensive, such as those with profanity, those that correspond to racial or gender slurs, or those that correspond to negative characterizations of people (for example, racist). “Sensitive” synsets are not inherently offensive, but they may cause offense when applied inappropriately, such as the classification of people based on sexual orientation and religion.
So far out of 2,832 synsets within the person subtree we’ve identified 1,593 unsafe synsets (including “offensive” and “sensitive”). The remaining 1,239 synsets are temporarily deemed “safe.” The unsafe synset IDs can be found here. We refrain from explicitly listing the offensive concepts associated with each; for a conversion, please see https://wordnet.princeton.edu/documentation/wndb5wn. We are in the process of preparing a new version of ImageNet by removing all the synsets identified as unsafe along with their associated images. This will result in the removal of 600,040 images, leaving 577,244 images in the remaining “safe” person synsets.
It is important to note that a “safe” synset only means that the label itself is not deemed offensive. It does not mean that it is possible, useful, or ethical to infer such a label from visual cues. While there can be scenarios where such visual labeling might be justified, such as identifying swimmers for safety monitoring, the ethics of classifying people must be carefully considered case-by-case for each application.
Offensiveness is subjective and also constantly evolving, as terms develop new cultural context. Thus, we open up this question to the community. We are in the process of updating our website to allow users to report additional synsets as unsafe.
Non-imageable concepts. The second concern is around concepts which are not inherently offensive, but may nevertheless be unsuitable for inclusion in an image dataset. ImageNet attempts to depict each synset in WordNet with a set of images. However, not all synsets can be characterized visually. For example, how do you know whether a person is a philanthropist from images? This issue has been partially addressed in ImageNet's automated annotation pipeline by only admitting images if there is a high degree of agreement between annotators[1]. But this safeguard was imperfect, and we have found a considerable number of synsets in the person subtree of ImageNet to be non-imageable — hard to characterize accurately using images.
Non-imageable synsets in ImageNet are a potential source of bias. When a non-imageable synset is (mis)represented with a set of images, we may end up with a biased visual depiction of the underlying concept. For example, images from the synset Bahamian (a native or inhabitant of the Bahamas) contain predominantly people wearing distinctive traditional Bahamian costumes. However, Bahamians wear this kind of costume only in special circumstances. This biased depiction is the result of both image search engines returning the most visually distinctive images for a synset and of human annotators only reaching consensus on the most distinctive images. This then results in a biased representation of the synset, which is particularly blatant for the synsets which are inherently non-imageable. In an effort to reduce this type of visual bias, we began by determining the imageability of synsets in the person subtree and removing those with low imageability.
We performed an annotation of the people synsets in terms of imageability, using workers from MTurk. We followed prior works in psycholinguistics that define imageability to be “the ease with which the word arouses imagery”[6-8] . We asked multiple workers to rate on a 1-5 scale on how easy it is to form a mental image of each synset, from very hard (1) to very easy (5).
We annotated the imageability of 2,394 people synsets that have been temporarily marked as safe or sensitive synsets. The results show that the median is 2.36, and there are only 219 synsets with imageability larger than 4. The complete list of imageability is available here.
Diversity of images. A third issue we identified is insufficient representation among ImageNet images. ImageNet consists of Internet images collected by querying image search engines[1], which have been demonstrated to retrieve biased results in terms of race and gender[4-5]. Taking gender as an example, Kay et al. find that when using occupations (e.g., banker) as keywords, image search results exhibit exaggerated gender ratios compared to the true real-world ratios. In addition, bias can also be introduced during the manual cleanup stage, as people are inclined to give positive responses when the given example is consistent with stereotypes[4].
ImageNet had taken measures to diversify the images, such as keywords expansion, searching in multiple languages, and combining multiple search engines. Filtering out non-imageable synsets also mitigates the issue: with stronger visual evidence, the workers may be less prone to stereotypes. Despite these efforts, the bias in the protected attributes remains in many synsets in the person subtree. It is necessary to study how this type of bias affects models trained for downstream vision tasks, which would not be possible without high-quality annotation of image-level demographics.
To evaluate the demographics within ImageNet and propose a more representative subset of images, we annotated a set of protected attributes on images in the person subtree. We considered U.S. anti-discrimination laws which name race, color, national origin, religion, sex, gender, sexual orientation, disability, age, military history, and family status as protected attributes[9-11]. Of these, the only potentially imageable attributes are color, gender, and age, so we proceeded to annotate these.
We follow the established protocols in annotating skin color, gender and age (details in our upcoming technical report). We annotated demographics on the 139 synsets that are considered both safe and imageable and that contain at least 100 images. We annotated 100 randomly sampled images from each synset, summing up to 13,900 images. The figure below shows the distribution of categories for different synsets, which mirrors real-world biases.
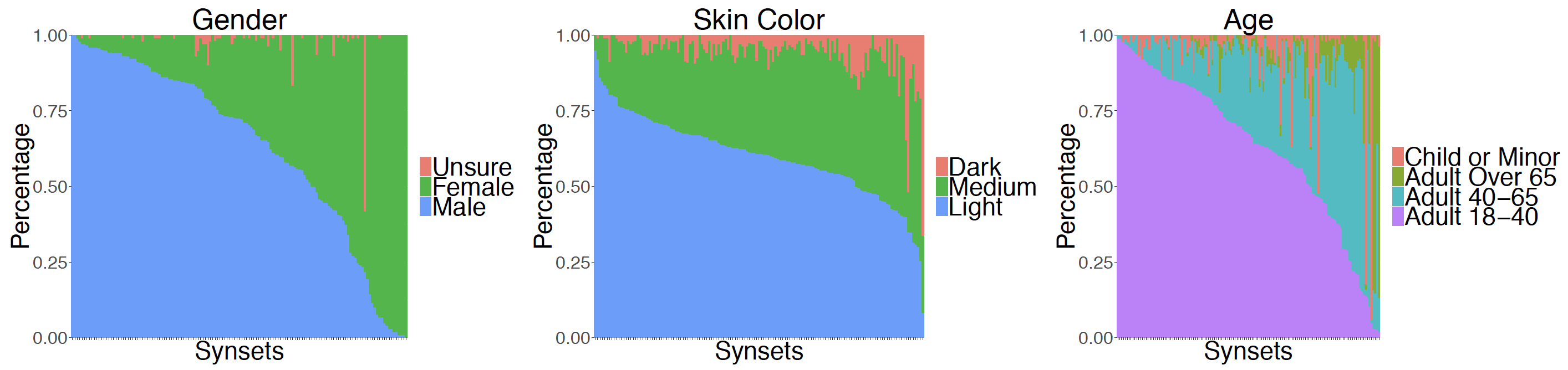
Figure 1: The distribution of demographic categories across the 139 safe and imageable synsets which contain at least 100 images. The size of the different color areas reveal the underrepresentation of certain groups.
Given the demographic analysis, it is desired to have a constructive solution to improve the diversity in ImageNet images. To this end, we are in the process of constructing a Web interface that automatically re-balances the image distribution within each synset, aiming for a target distribution of a single attribute (e.g., uniform balance of gender) by removing the images corresponding to the overrepresented categories (Figure 2). This balancing is only feasible on synsets with sufficient representation within each attribute category. For example, the synset baby naturally does not contain a balanced age distribution. Thus, we will allow the user to request a subset of the attribute categories to be balanced; for example, the user can impose equal representation of the three adult categories (“Adult Over 65”, “Adult 40-65” and “Adult 18-40”) while eliminating the “Child” category. Our future work includes collecting the rest of the annotations and publicly releasing the Web interface.

Figure 2: The distribution of images in the ImageNet synset programmer before and after balancing to a uniform distribution.
There is a concern that the user may be able to use this interface to infer the demographics of the removed images. For example, it would be possible to visually analyze a synset, note that the majority of people within the synset appear to be female, and thus infer that any image removed during the gender-balancing process are annotated as female. To mitigate this concern, we always only include 90% of images from the minority category in the balanced images and discard the other 10%. Further, we only return a balanced distribution of images if at least 2 attribute categories are requested (e.g., the user cannot request a female-only gender distribution) and if there are at least 10 images within each requested category.
Note that we have considered alternatives such as releasing the individual annotations, or collecting additional data for underrepresented attributes, each with their own pros and cons. A detailed discussion is available in our upcoming technical report.
Further Discussions
There is still much that remains to be done outside the person subtree, as incidental people occur in photographs illustrating other ImageNet synsets as well, e.g., in synsets of pets, household objects, or sports. It is likely (or at least hopefully) the density and scope of the problem is smaller in other subtrees than within this one, so the filtering process should be simpler and more efficient.
Finally, our effort remains a work in progress. Our research report is awaiting peer review and we will share it shortly. We welcome input and suggestions from the research community and beyond on how to build better and fairer datasets for training and evaluating AI systems.
*** Update on Oct 13, 2019: The above post describes one aspect of our effort to improve ImageNet data. Other parts of our effort have included addressing potentially questionable photos, blurring faces for privacy preservation, and updating the ImageNet Challenge data. We plan to release the first set of updates by the end of 2019, and will notify our community. Stay tuned!
References
- Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei "ImageNet: A large-scale hierarchical image database." 2009 IEEE conference on computer vision and pattern recognition. IEEE, 2009.
- Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei "ImageNet Large Scale Visual Recognition Challenge." International journal of computer vision 115.3 (2015): 211-252.
- Joy Buolamwini and Timnit Gebru. "Gender shades: Intersectional accuracy disparities in commercial gender classification." Conference on fairness, accountability and transparency. 2018.
- Matthew Kay, Cynthia Matuszek and Sean A. Munson. "Unequal representation and gender stereotypes in image search results for occupations." Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems. ACM, 2015.
- Safiya Umoja Noble. Algorithms of oppression: "How search engines reinforce racism." NYU Press, 2018
- Allan Paivio, John C. Yuille, and Stephen A. Madigan. "Concreteness, imagery, and meaningfulness values for 925 nouns." Journal of experimental psychology 76.1p2 (1968): 1.
- Ken J. Gilhooly and Robert H. Logie. "Age-of-acquisition, imagery, concreteness, familiarity, and ambiguity measures for 1,944 words." Behavior research methods & instrumentation 12.4 (1980): 395-427.
- Helen Bird, Sue Franklin, and David Howard. "Age of acquisition and imageability ratings for a large set of words, including verbs and function words." Behavior Research Methods, Instruments, & Computers 33.1 (2001): 73-79.
- U.S. House. 88th Congress, 1st Session. 88 H.R. 6060, "Equal Pay Act of 1963." Washington: Government Printing Office, 1963.
- U.S. House. 98th Congress, 2nd Session. 98 H.R. 5490, "Civil Rights Act of 1984." Washington: Government Printing Office, 1984.
- U.S. House. 101st Congress, 2nd Session. 101 H.R. 2273, "Americans with Disabilities Act of 1990." Washington: Government Printing Office, 1990.